이번에는 ICCV 2021에 accept 된 Kaist의 BiaSwap: Removing Dataset Bias with Bias-Tailored Swapping Augmentation 리뷰하려고 합니다. 자세한 내용은 원문을 참고해주세요.
Deep neural network는 보통 dataset에 존재하는 spurious correlation에 기반해서 prediction을 하는 경우가 많다고 합니다. 쉽게 말하면 ground truth라고 알고있는 대상을 보지 않고 correlated된 다른 feature를 기반으로 하는 경우가 많다는 것이죠.
이러한 것은 unbiased data distribution환경에서 generalization에 실패하는 경우도 많았기에 이러한 문제를 다뤘던 기존의 approach들이 있었다고 합니다. 흔히 생각해볼 수 있는 것은 pre-defined된 bias attribute를 통해서 하는 경우도 있지만, 이러한 것은 사실 비용도 비싸고 어려울 것이라는 추측은 간단하게 해볼 수 있을 것입니다.
그렇기에 최근 논문에서는 bias attribute를 unsupervised debiasing을 목표로 하는 방식을 취했습니다. 해당 방법에서는 unbiased 뿐만 아니라 biased sample에 대해서 classification ability를 유지하는 방향으로 update하는 것이 굉장히 중요했습니다.
본 논문에서는 explicit한 supervision없이 dataset bias를 하는 것과 bias-guiding sample과 bias-contrary sample 모두에서 좋은 성능을 보여주는데에 집중했다고 합니다.
여기서 bias-guiding sample은 bias가 존재하는 sample로서 새라면 뒤의 배경 하늘 정도가 되겠고, bias-contrary sample에서 object가 새라면 뒤의 배경이 용암일 확률이 적으니 그런 sample이라고 볼 수 있습니다.
본 논문에서 제안하는 BiaSwap은 translation 기반의 augmentation framework로서 각 이미지에서 나타나는 부분들을 다른 이미지로 transfer하여 추론 시키는 방식입니다. Bias가 easy-to-learn attribute로 구성되어있는 점에서 기인하여, bias attribute를 다른 exemplar image에 옮기는 방법이라고 할 수 있습니다. 그러면 bias-guiding sample을 bias-contrary로 옮겨서 debiasing을 한다 라고 생각하시면 좋을 것 같네요.
옮기는 위치는 Bias-relevant region의 CAM에서 빠르게 학습되어 나타나기 때문에 bias type을 정의하지 않고도 옮길 수 있다고 합니다.
Preliminary
$z_b$: bias-guiding attribute
$z_{-b}$: bias-contrary attribute
$z_{g}$: essential attribute
BiaSwap은 $z_g$를 보는 능력을 유지하면서 $z_b$를 $z_{-b}$로 transfer를 하는 것을 목표로 하는 것이라고 생각하시면 됩니다.
Debiasing approaches by removing bias with prior knowledge
기존 방법은 prior knowledge를 기반으로 AdaIN을 통한 style transfer-based augmentation method를 제안했는데, 해당 부분은 texture bias에 대해 robust하게 만들어주는 방법을 이었습니다.
Debiasing approaches by removing bias without explicit supervision
Supervision이 없는 경우에는 adversarial perturbation을 latent space에 부여해서 image를 synthesizing한 효과를 갖도록 하였습니다. 또한, early training phase에서는 bias 가 easy-to-learn한 성질을 가지고 있어서 generalized-CrossEntropy 참조를 통해서 biased train network를 조절된 weight로 학습하도록 하는 것이었다.
본 논문에서는 truely debiased classifier가 존재한다면 $z_g$를 잘 학습하는데, 이전 방법들은 biased dataset에 대해서는 심각한 performance degradation을 겪고 있다는 사실을 확인했고, 이는 bias-guiding attribute 자체를 피해가는 것이 문제일 것이라는 가정을 했다고 합니다.
그래서 본 논문에서는 bias-tailored (bias를 참조하는) augmentation을 사용해서 효과적으로 bias를 제거하고, generalized debiasing capability를 달성할 수 있을 것으로 기대한다고 합니다.
BiaSwap
Bias-guiding and bias-contraray group로 training sample을 효과적으로 나누는 method를 제안했습니다.
Explicit한 supervision없이 image에 대해서 bias label을 pseudo-labeling을 진행합니다. bias는 easy-to-learn이고, bias-contrary는 hard-to-learn임을 생각해보면 pseudo-labeling을 통해서 bias-guiding 인지 bias-contrary인지 confidence와 correctness를 관찰함으로써 구분이 가능합니다.
Binary category를 구별하기 위해 $f_{bias}$인 biased classifier를 Generalized Cross-Entropy (GCE)로 학습시킵니다. 참조 Noise robust하다는 특성을 고려하여 gCE는 biased representation을 amplify를 할 수 있게 되는데, 그것은 ground truth 확률 $p_y$에 의해 결정되게 됩니다. (GCE gradient식을 참조하시면 좋습니다.)
GCE loss의 역할은 학습이 쉬운 sample에 더 많은 importance를 부여하여 GCE로의 biased classifier의 학습이 가속화되게 하는 역할을 합니다.

그러고, 위 식처럼 각 sample의 bias score를 얻을 수 있는데, bias가 많이 되어있을 수록 score가 낮아지는 형태로 계산을 합니다. 위 식으로 부터 bias인지 아닌지를 binary하게 나타낼 수 있고 이를 다음과 같은 pseudo bias label $~y_{bias}$로 얻을 수 있으며, 해당하는 기준은 여러 sample읠 평균을 바탕으로 그 위는 unbiased, 아래는 biased로 구분합니다.
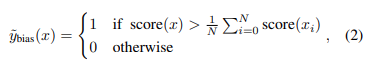
Bias-tailored swapping autoencoder
주어진 pair에 대해서 image-to-image translation method인 Swap AE를 사용해서 bias-contrary sample로 bias-aligned sample을 translation하는 방법을 제안합니다.
기존 SwapAE와 달리 bias-aware attributes를 translate하기 위해서 patch cooccurrence discriminator를 바꿔서 Bias-tailored patch discriminator를 제안합니다.
Swapping Autoencoder
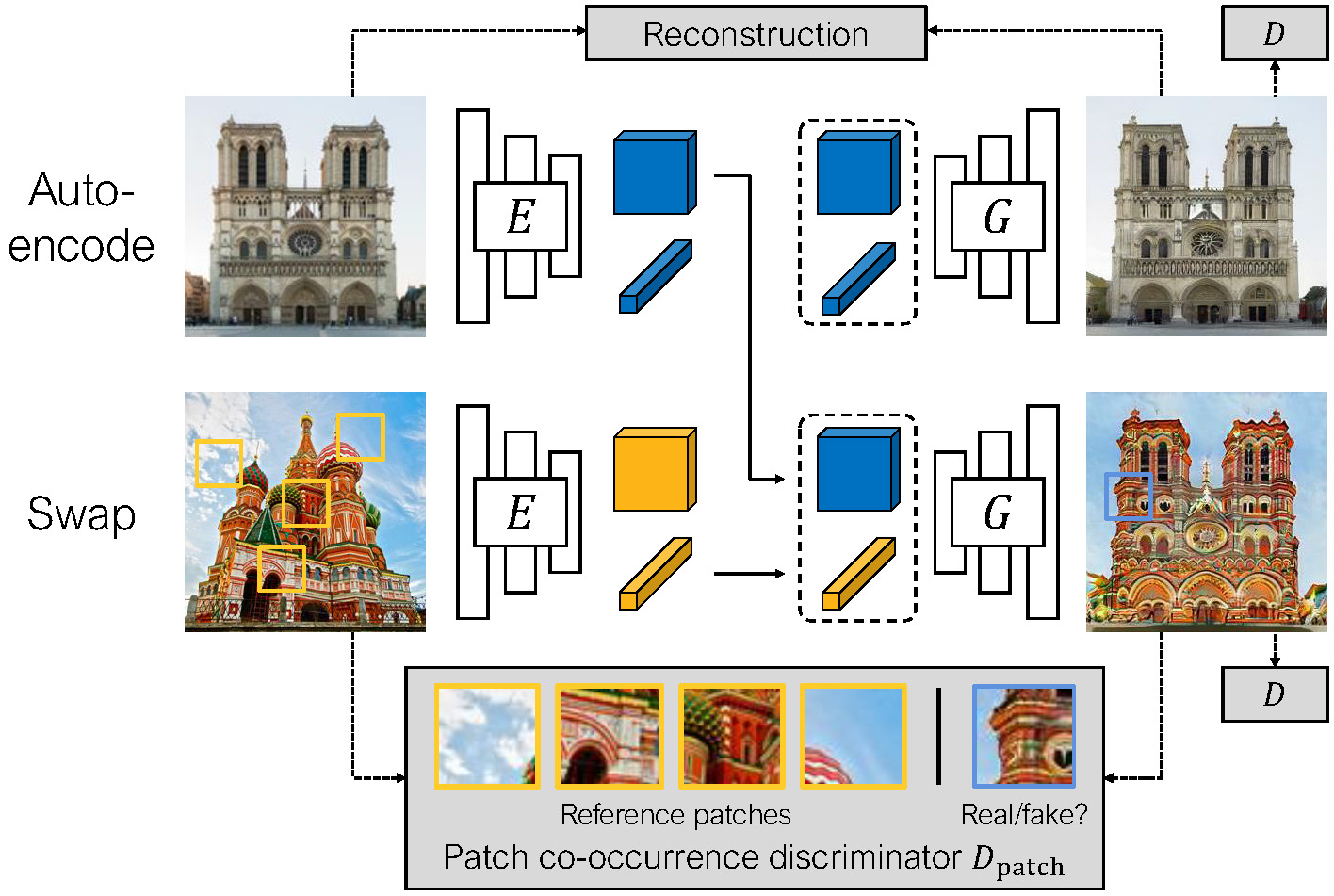
Swap AE는 Auto encoder의 기본적인 구조를 따르는데 encoding 된 latent vector가 style vector $z_s$와 content feature $z_c$로 구성이 되며, AE의 reconstruction loss와 생성된 이미지의 adversarial loss를 활용합니다. 여기서 $D$는 discriminator이다.
$$ L_{recon}(E,G)=\textit{E}{x\sim\chi}[||x-G(E(x))||^2_2]$$ $$ L_{GAN,recon}(E,G,D)=E_{x\sim\chi}[-logD(G(E(x)))] $$
SwapAE는 여기서 stlye을 translate을 하기 위해서 한 이미지 $x_1$의 latent vector중 $z_s^1$을 $z_c^2$와 결합하여 Generator에 넘겨서 학습하는 형태를 사용합니다. 여기서 Patch co-occurrence discriminaotr $D_{patch}$가 style을 정확하게 random sample된 patch로부터 만들어내도록 합니다. 이를 정리하면 아래의 식처럼 $x^{2}$로 부터 여러개의 patch를 crop한 것들과 $x^1$과 $x^2$의 latent끼리 합쳐진 tuple로 부터 생성된 이미지를 배우게 되어 아래의 식처럼 objective가 구성되게 됩니다.
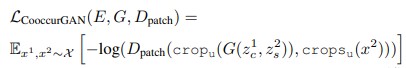
이 때, image를 더 realistic하게 만들기 위해서 SwapAE 논문에서는 $x^1$과 $x^2$가 같지 않게 GAN의 adversarial loss가 되도록 구성했습니다.
CAM-based patch sampling
기존 논문에서는 $D_{patch}$에 ramdom하게 sample된 patch가 들어가게 되어있는데, 이는 biased sample의 입장에서 certain attribute에 상관 없이 style이 들어가게 된다는 사실을 알 수 있습니다. 그런 점에서 corresponding한 style을 추출시킬 필요가 있었습니다.
Bias classifier인 $f_{bias}$를 활용해서 CAM방식으로 spatial region의 어떤 부분이 classify되는지를 활용합니다. Bias classifier이기 때문에 각 class에 대한 activation point를 확인할 수 있을 것이라 생각했습니다. logit for class $c$는 다음과 같이 나타낼 수 있게 되고 importance를 다음의 식으로 나타낼 수 있습니다.
$$I_c(x,y)=\sum_{x,y}{\sum_{k}{w^c_k f_{bias,k}(x,y)}}$$
이 때, $f_{bias,k}(x,y)$는 흔히 아는 global average pooled actiation map이다. 이렇게 되면 biased classifier에 대해서 large value인 $I_c$가 각 location이 bias attributes를 얼마나 가지고 있는지를 나타낼 수 있게 됩니다. Sampling probability로 만들기 위해서 본 논문에서는 값을 softmax를 취하게 됩니다. 본 값을 가지고 sample된 patch를 Discriminator와 Generator에 활용하고 bias-tailored patch discriminator의 objective는 아래식으로 구성됩니다.

이렇게 생성된 이미지는 original image와 같이 섞여져 reasonable한 sample을 만들어낸 후, 적절한 비율을 사용하여 $f_{debias}$ classifier를 classification loss로 training하게 됩니다.
Experiments

다시 상기시키자면, 본 논문의 목적은 bias guiding과 bias contrary sample 모두 잘하는 것을 목적으로 합니다. 결과적으로 unbiased sample에 대해서는 잘해지기는 했지만, 논문에서 제안한 만큼 unbiased를 잘 풀어내는 것 같지는 않았습니다. (Corrupted cifar10 0.5%에서 29%는 사실 아쉽기는 한 것 같습니다.)
그래도 real world에 대해서는 제법 잘한다는 사실을 알 수 있습니다. (bFFHQ는 0.5% / BAR dataset)
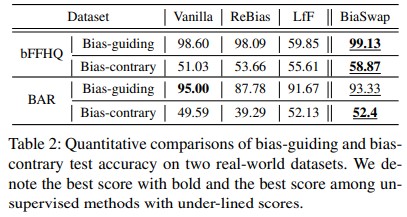
더 자세한 내용은 본문을 참조해주세요.




댓글