이번에는 NeurIPS 2021에 accept 된 Kaist와 Kakao의 Learning Debiased Representation via Disentangled Feature Augmentation 리뷰하려고 합니다. 자세한 내용은 원문을 참고해주세요.
최근의 Deep Neural Network는 주변 속성들을 기반으로 decision을 진행하고, 이러한 것은 target variable과 correlation이 강하게 존재한다. 이런 모델은 dataset bias로 부터 학습된 biased model이라고 한다.
Biased dataset은 target variable에 맞는 것이 주로 나타나는 속성을 포함한다. (이를 bias attributes라고 부른다.) 논문에서는 새와 그 주변의 하늘 정도를 얘기한다.
또한, 이러한 데이터에도 물론 intrinsic attibutes도 존재하며, 이는 실제로 특정 class를 구성하는 attribute이다. 논문에서는 새의 날개와 같은 부분을 나타낸다고 한다.
이러한 속성들은 model이 task를 빠르게 배우게 하는 방법을 제공하지만, biased attributes와의 correlation으로 인해 generalization에 실패하는 요인으로 작용하기도 한다. 그래서 본 논문에서는 다음과 같은 두 가지의 data sample을 정의한다.
Bias-aligned sample: Bias와 Intrinsic attribute간의 strong correlation을 갖고 있는 dataset sample을 의미한다.Bias-conflict sample: Bias와 Intrinsic attribute간의 correlation이 적은 sample이다.
이렇게 biased model을 덜 구성하게 하기 위해서, 이전 방식은 보통 specific bias type을 미리 정의하여 풀려고 하거나 bias attribute는 model에 학습이 빨리된다는 점을 기반으로 debiasing을 하려고 한다. 미리 정의 하는 경우에는 정의와 다른 경우, 성능이 낮고, 정의 하기 어렵다는 단점이 있다.후자의 경우에는 debiasing을 기존 방법이 re-weight를 통해서 bias-conflicting sample대신에 bias-aligned sample을 de-emphasizing하는 방식으로 진행해왔습니다. 하지만, data sample의 부족으로 적절하게 debaising하기에는 generalization ability 가 부족했다는 것이 문제였습니다.

이러한 부분을 보여주기 위한 것이 다음의 실험입니다. Sampling ratio를 통해서 앞서 말했던 de-emphasizing이 될 수 있고, diversity ratio가 낮을 수록 더 낮은 accuracy를 보이는 것을 알 수 있습니다. 하지만 diversity ratio가 높아지면 많은 성능 향상을 보임을 알 수가 있습니다. 이를 통해서 debiasing에서 diversity가 차지하는 요소도 큼을 알 수 있습니다.
본 논문에서는 debiasing을 위해서 data augmentation method들을 설명하고 있으며, 이를 통해서 이루어내려고 한다고 말하고 있습니다.
기존의 method에서는 AdaIN과 같은 adaptive instance normalization에 의한 style transfer를 통해서 texture bias를 다룰 수 있다고 주장합니다. 하지만, texture bias뿐만아니라 다양한 종류의 bias가 있는 만큼 모두 다룰 수 있어야 한다고 주장하고 있습니다.
Bias attribute이야기로 돌아가서 해당 속성은 보통 target label이 속한 부분과 같이 entangle되어있는 것을 알 수 있습니다. 이렇기 때문에 intrinsic attribute만 배우는 것이 굉장히 어렵습니다. Bias attribute는 dataset의 많은 부분을 차지하고 있기 때문에 diverse할 수 있으므로 bias-aligned sample의 instrinsic한 부분만 잘 가져와서 학습하면 되지 않을까? 라고 주장하고 있습니다.
Strong하게 correlated 되어있는 두 속성을 2개의 encoder와 classifier로 나누어서 사용하면 되지 않을까라고 생각한 것입니다. 두 속성을 각 encoder와 classifier로 분리하는 방법을 제안합니다.
Bias attribute는 빠르게 학습된다는 점에서 착안해서 이전의 work에서 제안된 relative difficulty score를 활용해서 GCE(Generalized Cross Entropy)로 학습된 $E_b$와 $C_b$를 bias attribute를 뽑아내는 기제로 활용합니다.
또한, CE는 instrinsic attribute를 뽑아내는 $E_i$와 $C_i$를 사용하여 상대적 점수를 계산합니다.

해당 식은 위식으로 GCE는 학습속도가 상대적으로 느리지만 robust하게 학습되는 loss term이므로 $C_b$의 CE값이 클 때, bias-conflicting sample로 간주할 수 있게 됩니다.
이런 점수를 바탕으로 intrinsic classifier와 feature extractor를 더욱 강하게 학습시키는 disentanglement objective를 제안합니다.
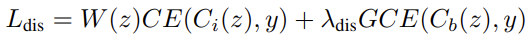
이러한 식으로 학습하는 구조는 다음과 같습니다.

이제 점수를 바탕으로 학습하는 것까지는 마무리를 했고, 그래서 어떻게 diversity를 줄 것인지에 대한 얘기를 하지 않았으니 진행해보도록 하겠습니다.
위 그림처럼 진행을 하게 되는데, 직관적으로 이해를 해보자면 $E_i, C_i$에는 intrinsic attribute를 갖는 feature extractor고, $E_b, C_b$에는 bias attribute를 갖고 있다고 가정을 하면, feature swap을 통해서 intrinsic attribute에 다양한 bias attribute가 섞여서 들어간다는 점을 생각하면 각 classifier는 다양한 intrinsic attribute를 갖는 bias-conflicting sample을 갖는다는 것을 알 수 있습니다.
하지만, 초기 몇 epoch은 feature를 잘 뽑아내지 못하기 때문에 해당 부분만 스킵하고 feature swap을 진행한다고 말하고 있으며 알고리즘은 다음과 같습니다.

Bias conflicting을 위한 setting의 dataset 을 보여주는 데 다음과 같습니다.

가장 직관적인 것은 color mnist인데요, training dataset은 점선 위의 부분이고 test set이 아래처럼 색이 다른 값을 사용하여 test한다는 것을 생각해 볼 수 있습니다.
Experiment
실험은 위에서 보여진 이미지 데이터셋으로 진행하며, 비교군은 앞서 설명드린 방법들 입니다.
HEX, EnD, ReBias는 bias type을 정의해주어야하며, LtF와 Vanilla는 해당 부분을 정의하지 않고 de-emphasizing만 진행한 방법론입니다. (자세한 내용은 해당 논문을 참조해주세요)
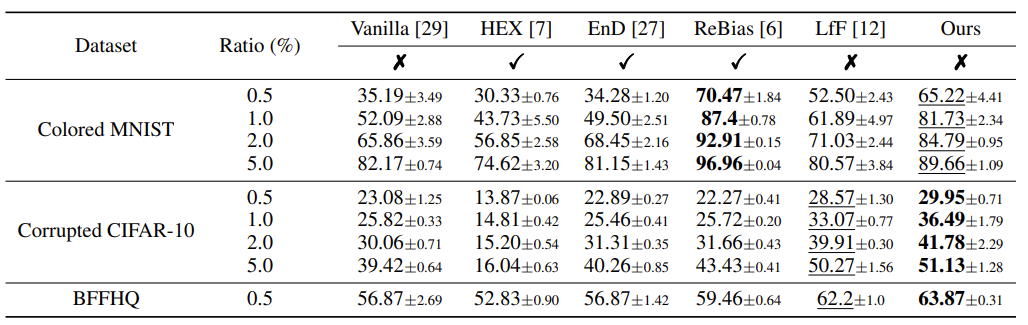
Color MNIST는 너무 극단적이라 상대적으로 낮은 점수를 보이는 것을 제외하면, 다른 방법론에 비해서 성능이 뛰어남을 알 수 있습니다.

각 부분이 실제로 이 method를 동작시키는데 기여한 기여도입니다. scheduling의 중요성을 볼 수 있습니다.
저는 ablation study가 더 재밌었던 것이 많아서 해당 부분을 설명드리고자 합니다.

Disentangled representation의 2d projection입니다. 각 class의 분포와 bias attribute의 분포를 나타낸 것입니다. $z_i$ (a)는 intrinsic attribute의 분포이고, $z_b$ (b)는 bias attribute이고, (i)과 (ii)는 각각 target label과 bias label입니다. 이렇게 보면 약간의 noise빼면 대체로 잘 cluster되어 있는 것을 확인할 수 있습니다.

위의 projection을 보다가 표를 보면 오.. 라는 생각이 들었습니다. 사실 swap된 feature가 정상적인 prediction이 될까라는 생각이 들었는데, swap된 feature의 prediction에서도 생각보다 잘 값을 뽑아내는 것을 알 수 있습니다. 흥미로운 점은 Colored MNIST의 original feature에서 bias label의 정확도가 instrinsic classifier에서 더 높다는 점입니다. (Original row의 Bias column)
자세한 내용은 논문을 참조해주시기 바랍니다 :)




댓글