이번에는 AAAI 2021에 accept 된 SnapMix: Semantically Proportional Mixing for Augmenting Fine-grained Data을 리뷰하려고 합니다. 자세한 내용은 원문을 참고해주세요.
Introduction
Data mixing augmentation은 딥러닝 모델을 학습시키는데에 어서 효과적인 면모를 보여왔습니다. 그 중에서 MixUp, CutOut, CutMix와 같은 논문들은 효과적인 발전을 이끌어왔습니다. 이러한 data mixing augmentation은 training distribution을 확장시키고, data를 deep learning model에 기억시키는 현상(overfitting)을 줄임으로서 model generalization을 높이는 역할을 해왔습니다.
하지만 이러한 역할에도 불구하고, fine-grained data에서는 약한 모습을 보여왔는데, label noise(label을 섞는 행위)가 이러한 모습을 약화시킨다고 합니다. 왜냐하면 각 class를 구분하는 요소가 굉장히 작은 위치에 존재하여 label noise가 도움이 안되기 때문입니다.
또한, CutMix의 경우, 사진 부분의 중요도와 관계없이 단순히 잘라서 넣기 때문에 large area가 아니면 관련 없는 부분이 삽입되는 경우가 많을 수 있었습니다. 그러므로 mixing label을 proportion 기반으로 진행하는 것은 효과적인 방법은 아니라는 것입니다.
그래서 본 논문에서는 semantically proportional mixing 을 채택해서 이러한 문제를 하려고 한다고 합니다. Class Activation Map(CAM)을 사용하여 가중치에 따라서 mixed image에서의 label별 비율을 선택하는 방식을 사용한다고 합니다.
Related Works
Fine-Grained Classification
본 논문은 fine-grained dataset에서 실험이 이루어졌는데, fine-grained dataset은 말 그래도 세세하게 봐야 구분이 되는 dataset으로 cifar10, imagenet과 달리 비행기 dataset이라면 비행기 종류에 따라 진행된다는 의미입니다.
Data augmentation
Data augmentation방법론중 두 가지는 regin-erasing based and data mixing인데, CutOut이 전자의 대표적인 것이고, CutMix와 MixUp과 같은 방법론이 후자입니다.

간단하게 이미지로 나타내면 다음과 같은데 Cutout의 경우 사진의 일부분을 잘라내는 것이라면, Mixup과 CutMix는 다른 사진과 일정 비율 label과 image를 섞는 것입니다. Mixup은 이미지 전체에서 pixel비율을 random으로 섞지만, cutmix는 이미지의 일정 부분을 random으로 섞는 것을 의미합니다.
CutMix의 경우, classification task들과 weakly-supervised localization tasks에서 훌륭한 성능을 보여주었다고 합니다. 이러한 제안에도 불구하고 label을 mixing하는 것에 저자는 의문을 가졌다고 말합니다. 그저 mixture pixel들의 수치적인 값에 의존하기에 정확하게 그 label에 맞냐는 의문이 남아있었다고 합니다.

그래서 제안한 것이 다음의 방식입니다.
Method
본 논문에서 제안한 방식은 Sementically Proportional Mixing(SPM)을 통한 SnapMix입니다.

위 식을 통해 이미지를 element-wise multiplication을 진행하고, lambda만큼의 비율을 label mixing을 진행하는데 이때의 M값을 조정하는 것이 목표입니다.(I= image) 하지만 object part를 $M_{lambda}$가 가리키지 않아 y의 label mixing이 적절하게 이뤄지지 않는다면, 특히 Fine-grained recognition task에서 더 자세한 부분을 봐야하는 만큼 적절하지 않다고 생각했다고 합니다. 그래서 Class Activation Map(CAM)을 통해서 이렇게 class-specific한 부분을 봄으로써 region의 비율에 따라서 정확하게 mixing을 할 수 있을 것이라 여겼다고 합니다. CAM은 각 클래스에 대해서 model이 어디 부분을 보고 활성화되는지 확인할 수 있는 방법이라고 생각하면 좋을 것 같습니다.
알고리즘을 따라가 보면,
1. $lambda$를 random generation한 후, 해당 비율에 맞게 a와 b 이미지의 bounding box를 만듭니다.
2. a이미지는 CAM값을 normalize하여 bounding box의 외각에 있는 값의 합을 label a의 값으로 갖습니다. 이미지는 bounding box 외각을 사용합니다
3. b이미지는 CAM값을 normalize하여 bounding box의 내각에 있는 이미지를 a의 bounding box의 크기로 resize한 후, 이미지를 합성하며 label b는 normalize 한 값의 합으로 갖습니다.


SPM(Semantic Percent Map)은 여기서 pixel과 label사이의 상관 비율을 정량화 하는 것이라고 하는데 $S(I_i)$로 나타내고 다음 식과 같습니다. 사실상 CAM형상을 normalize 한 것입니다.

여기서의 특징은 Image label의 합이 1이 아닌라는 것 입니다. bounding box 내부외부에서의 normalized sum 값을 기반으로 선택하지만 label a, label b의 합이 1일 수도 아닐 수도 있다는 것을 의미합니다.
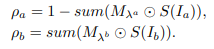
Experiment
이러한 방법론을 fine-grained dataset에 적용하였고, 대표적인 CUB-200-2011, Stanford-Cars, FGVC-Aircraft에 적용한 결과는 다음과 같습니다.

성능이 타 augmentation 방법, 특히 CutMix에 비해 잘나온 것을 확인하실 수 있습니다.
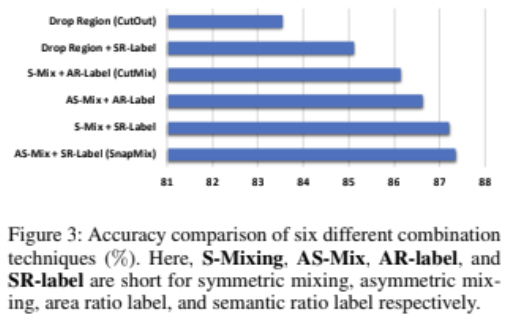
이미지를 mixing하는 방법끼리의 비교인데 label mixing방법도 다르므로 이를 비교하는 그래프인데, SR이 Semantic ratio label로 SnapMix에서 사용하는 방법으로 CutMix에서 사용한 Area ratio labeling방법 보다 더 잘나오는 것을 확인할 수 있습니다. Asymmetric mixing이 CutMix보다 잘나오는 것을 통해 관찰하는 대상의 부분을 활용하여 mixing을 하는 것이 더 도움이 됨을 확인할 수 있겠네요.

확실히 다른 Augmentation method에 비해서 합리적인 위치를 보고 prediction하는 것을 보실 수 있습니다.
Conclusion
Class Activation Map을 활용해서 dataset을 augmentation을 통해서 model의 성능을 올릴 수 있는 좋은 방안인 것 같습니다. label 분배에 대해서 고민한 흔적을 합이 1이 아니어도 된다는 고정관념을 타파한 논문이라고 생각합니다. 궁금한점은 pretrained 없이 초기에 학습이 잘되는 곡선이 그려질지도 궁금한 부분입니다. 초기에는 MixUp CAM 이미지처럼 합성이 되면서 혼동이 있을 것 같다는 생각이 드는데 어떨지 모르겠네요.




댓글