이번에는 ICLR 2020에 poster session에 accept 된 Fast is better than free: Revisiting adversarial training 을 리뷰하려고 합니다. 자세한 내용은 원문을 참고해주세요.
Introduction
Deep neural network는 많은 application 분야에서 성공을 거두고 있지만, robust deep neural network는 아직 research 분야로 남아있을 정도로 발전이 더뎠다고 합니다.
Robust of neural network란 adversarial example에 의해 model이 제대로 본연의 task의 문제를 해결하지 못한다는 것입니다. 이를 adversarially perturbed example이라고도 부르며, decision boundary를 넘게 만드는 이미지를 만들어 classify가 정상적으로 되지 않게 만드는 것을 의미합니다.
그래서 이러한 부분을 막기위해서 adversarial training이라는 분야를 통해서 adversarial attack에 대응할 수 있는 분야가 발전해오고 있었습니다.
이러한 방법론들은 대체로 additional cost를 필요로 하고, 일반적인 training에 대해서 굉장히 많은 시간의 소요를 문제로 합니다. 그래서 최근 논문들은 adversarial training에 대해서 computational complexity를 줄이려고 노력한 논문들이 많다고 합니다. 하지만 여전히 standard training에 비해서 굉장히 느리다고 합니다.
그래서 본 논문에서는 adversaral training 중에서 가장 유명하지만 비효과적인 것으로 여겨져온 FGSM (Fast Gradient Sign Method)에 random initialization이 추가되면서 인식이 개선된 것처럼 이러한 부분들을 다시 확인하면서 개선할 여지를 파악하고자 한 논문입니다.
Related Work
이 부분은 저도 사실 잘 몰라서 조금만 자세하게 작성하도록 하겠습니다.
기존 연구에는 FGSM, R+FGSM, PGD adversary, 등등이 있었으며, 이를 통해 adversarial attack 에 방어할 수 있는 training method가 존재했습니다.
FGSM(Fast Gradient Sign Method)
기존 input에 대해서 model에 inference 시킨 후, 목표로 하는 class가 있는 경우 input에 gradient descent를 해당 클래스로 시켜서 adversarial example을 만들어 이를 학습 시키는 기법 (FGSM 자체는 adversarial example을 만드는 것까지)
목표로 하는 class가 없는 경우 input에 gradient ascent를 ground truth에 대해서 진행시켜서 adversarial example 생성(FGSM 자체는 adversarial example을 만드는 것까지)
R+FGSM
FGSM에서 attack하는 noise의 initialization을 random으로 진행시킨 후 gradient를 noise에 더하여 adversarial example을 생성하는 방법
PGD
gradient ascent를 adversarial example을 생성할 때, FGSM과 같은 방법을 $\alpha$ step만큼 중복시켜서 진행하여 adversarial example을 만드는 기법
PGD의 경우 여기서 optimization trick인 momentum을 사용하여 adversary를 증가시키는 방법 등이 있었다고 합니다.
하지만 PGD의 경우, Adversarial defense에서 높은 성능을 보여왔지만, strong PGD adversary는 inner loop가 굉장히 많기 때문에 이러한 PGD training에서 높은 정확성을 갖는 모델을 찾기는 굉장히 오래걸리고 computationally expensive한 경향이 있다는 사실을 확인했었습니다.
Adversarial training overview
Adversarial training은 adversarial attack에 대해서 robust한 learning network를 만드는 방법으로 지목받아 왔습니다. network $f_\theta$는 robust optimization problem에 대해서 다음과 같은 min-max problem으로 나타납니다.

Crossentropy loss에서 delta를 최대화 시키는 방향으로 image의 noise를 만들어 이미지에 입히되, loss가 최소화 되는 방향으로 $\theta$를 가져가게 최적화 하는 것입니다.
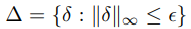
정의된 epsilon에 따라서 delta값은 달라지며, Madry 논문의 PGD training에서 사용하는 값입니다.
이러한 형식은 adversarial attack을 사용해서 maximization을 approximate하고, $\theta$에 대해서 gradient descent를 사용하는 약간의 일반적인 학습의 변형으로서 진행합니다.
이렇게 되면 FGSM의 값과 같이 다음의 식으로 L_inf perturbation이 됩니다.(FGSM attack 진행방식)

이러한 inner maximization에 대한 better approximation으로 multiple smaller FGSM step을 $\alpha$로 가져가게 된다면 iterative하면 set ∆ 로 projection되는데 여러번 무작위로 이를 반복하면 maximization approximation value가 최대화되어(반복 누적으로 인한 최대화) 더 강력한 attack을 만들 수 있고, 이를 가지고 학습하면 robust neural network 를 만들 수 있게됩니다 (PGD adversary 방식)
알고리즘 1을 보면 좀더 자세하게 알 수 있는데 delta에 대해서 iterative하게 udpate해서 clipping을 진행하는 것을 확인할 수 있습니다.

이러한 PGD adversarial training은 하나의 epoch t에 대해서 O(MN)의 complexity를 가지므로 굉장히 오래걸린다는 사실을 알 수 있습니다.
이러한 부분을 개선하기 위해서 Free Adversarial Training이 나왔는데, FGSM step을 $\alpha=\epsilon$으로 가져가서 N번 iteration을 진행하면서 모델을 업데이트합니다. 즉, 알고리즘 2에서처럼 PGD에서의 iteration을 진행하면서 noise와 neural network를 동시에 업데이트를 진행하는 방식입니다. 추가적으로 전체 epoch T을 N iteration만큼 나눠서 T/N만큼 진행하더라도 괜찮게 구성을 한 것이죠. 당연히 PGD보다는 빠르지만 원래 O(1)의 standard training과 비교하면 O(M)이라는 큰 complexity가 남는다는 사실을 알 수 있습니다. 그 시간은 imagenet에서 2일정도 더 걸린다고 하네요.

이러한 문제점들이 많아서 시간이 오래걸리니 이러한 부분을 개선하자는 것이 본 논문의 취지입니다.
그래서 Fast Adversarial Training 방법을 제안합니다.
특징은 noise를 uniform sampling한 후 이러한 noise에 gradient값을 더한 후에 clipping을 통해서 perturbed noise를 만들어내서 parameter를 업데이트시킬 image를 만들어 내는 것입니다. 이렇게 하게되면 adversarial step이 필요하지 않기 때문에 O(1)로 줄어들 수 있습니다. (물론 backpropagation이 있으니까 굳이 따지자면 O(1+a)정도 되겠습니다.) 알고리즘 3를 참고하세요!

아래 표를 보시면 FGSM의 속도가 눈에 띄게 빨라진 것을 확인하실 수 있습니다.

모든 adversarial method에서 사용이 가능하고, 여러 technique을 사용해서 비교해본 결과 속도가 비교 불가할정도로 빠른데 성능은 PGD를 제외하면 유사하게 나오는 것을 확인할 수 있습니다.
Revisiting FGSM Adversarial training
FGSM이랑 제안한 방법이 굉장히 유사하지만, free adversarial training은 실험적으로 PGD attack에 대해서 robust 한 경향성을 보였다. 그 이유는 free adversarial training은 perturbation을 이전 iteration에 대해서 진행한 것을 사용하기 때문이라고 생각했기 때문이라고 합니다. 하지만, 다른 minibatch data에 대한 adversarial perturbation(알고리즘 2의 N에 대한 for문)을 이전 minibatch의 것을 사용해도 되냐는 의문이 남죠. 그래서 본 논문에서는 그냥 non-zero initial perturbation이 의미가 있는 것(알고리즘 3의 uniform부분)은 아닐까라는 가정으로 본 연구를 시작했다고 합니다.
그래서 FGSM을 random initialization에서 진행을 해보았다고 합니다. 이는 우리가 알던 사실과 달리 FGSM을 약간 조정하면 PGD보다 더 effective하게 PGD learning을 할 수 있었다고 합니다. 이러한 검증 실험으로 이전 minibatch에 대한 adversarial perturbation으로 학습한 모델과 non-zero initialization으로 adversarial training을 진행하였고, 이를 확인해보니 PGD adversarial attack에 강하다는 것을 확인했다고 합니다.
기존의 method와 유사하고 제약이 더 적지만 기존 method (R+FGSM)보다 더 높은 성능을 보여주었다고 합니다. 이러한 initialization에 대한 effect를 확인하기 위해서 $\epsilon=8/255$ 로 고정하여 기존 FGSM에서 앞서 말씀드린 두 부분을 확인했고 해당 결과가 random init이 더 높게 나왔다고합니다.
DAWNBench improvement
DAWNBench competition에서 엄청나게 시간이 빠르게 나오는 classifier를 제시해서 이러한 부분을 사용하여 얼마나 제안한 방법이 효과적인지 확인하고자 하였습니다. 또한 다른 가속화하는 방법들을 사용해서 computational cost와 성능을 확인하였습니다. (Mixed precision, cyclic learning rate)


저자는 확실히 성능도 PGD에 필적할 만큼 좋은 성능이지만 (table 4) 시간이 빠르다는 것을 많이 강조하고 싶었던 것 같습니다. 또한, defender에게 더이상 강한 adversaries로 학습할 필요가 없음을 제시하면서 마무리를 지었습니다.
이상입니다.




댓글